
![]()
初めまして!今年1月からジョインしたyukiyanです。
feedforceではアプリケーションエンジニアを担当しています。
最近、弊社のあるプロジェクトにて Google BigQuery を導入しました。
その際、学びがいくつかあったので知見として投下します。
※ Railsのプロジェクトなので、一部のサンプルコードにRailsの表現も含まれています。
BigQueryとは
BigQueryとは、Google Cloud Platform(以下、GCP)が提供するクラウドサービスです。
超でかいデータをSQL風のクエリで数秒で解析できます。
5億件のデータを3秒程度でフルスキャンできます。
もっと知りたいという方は、hadoop - Googleの虎の子「BigQuery」をFluentdユーザーが使わない理由がなくなった理由 #gcpja - Qiitaを参照してください。
gemの選定
gemについては、公式リファレンスで紹介されているgoogle/google-api-ruby-clientを使うと良いと思います。
このgemはまだalpha版でしたが、使い勝手としては十分だと思います。
また、Google API Clientとして機能するgemなので、BigQueryだけで無く、Google Cloud Storageなどのサービスにも対応しています。
公式以外の便利そうなgemも試してみた
当初は、公式ではありませんが、google-api-ruby-clientをラップして作られたabronte/BigQueryというgemを使っていました。
このgemを使うことでgoogle-api-ruby-clientよりシンプルにBigQueryにAPIを投げられます。
しかし、使えないAPIメソッドや公式で非推奨なメソッドを使っている箇所があり、issueやPRを出してマージして頂いたりしましたが、結局プロダクションでの利用は断念しました。
認証
BigQueryのAPIを使う際には認証が必要です。
これは、BigQueryだけでなくGCPのサービスのAPIを叩く際には、共通して必要な作業です。
GCPはOAuth 2.0を用いた認証方法を提供しています。
その中でも、Service Accountsという方式を使った認証方法をご紹介します。
これは、サービス固有のP12(PKCS12)形式の秘密鍵を発行して認証を行い、APIを叩くという方式です。
P12形式の秘密鍵の取得方法
Google Developers Consoleから以下のようにして取得できます。
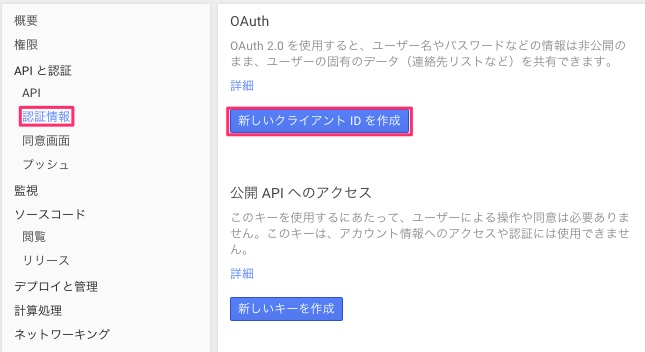
「認証情報」を選択後、「新しいクライアントIDを作成」を押下。
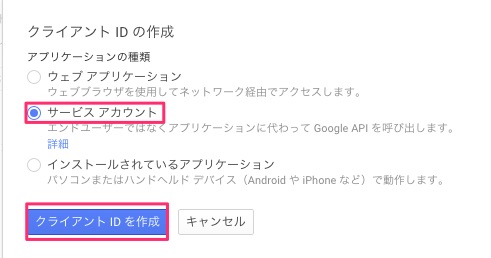
ポップアップ画面が表示されるので「サービスアカウント」を選択し、「クライアントIDを作成」を押下。
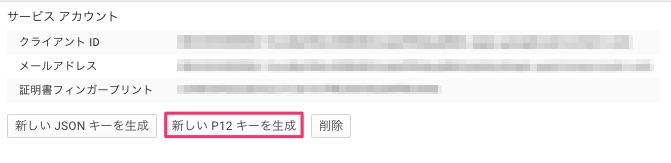
「新しいP12キーを生成」を押下すると、p12形式の秘密鍵がダウンロードされます。
ここで取得した秘密鍵を使って、google-api-ruby-clientから認証を行い、APIを叩きます。
google-api-ruby-clientを使った場合の認証のコード例
READMEにも説明がありますが、以下のようにして認証を行います。
require 'google/api_client'
client = Google::APIClient.new(application_name: 'sample', application_version: '0.0.1')
key = Google::APIClient::KeyUtils.load_from_pkcs12('p12のファイルパス', 'notasecret')
scope = [
'https://www.googleapis.com/auth/bigquery',
'https://www.googleapis.com/auth/cloud-platform',
'https://www.googleapis.com/auth/devstorage.read_only',
'https://www.googleapis.com/auth/devstorage.read_write',
'https://www.googleapis.com/auth/devstorage.full_control'
]
client.authorization = Signet::OAuth2::Client.new(
token_credential_uri: 'https://accounts.google.com/o/oauth2/token',
audience: 'https://accounts.google.com/o/oauth2/token',
scope: scope,
issuer: '123456789@developer.gserviceaccount.com',
signing_key: key)
client.authorization.fetch_access_token!
api = client.discovered_api('bigquery', 'v2')
load_from_pkcs12というメソッドの第一引数に先ほど取得した秘密鍵のファイルパスを渡します。- scopeとは、どのAPIを使用できるようにするか判断するためのパラメータです。各APIメソッドごとに必要なscopeはドキュメントに載ってます。上記のコードではJobs.insertの場合のscopeを用いてます。
- issuerは、サービスアカウントのメールアドレスです。Google Developers Consoleで確認できます。
プロジェクトとデータセットという概念
GCP 内の 1サービスである BigQuery にデータを投入し管理する際、その単位としておさえておきたい概念として、 "プロジェクト" と "データセット" というものがあります。
プロジェクトとは
プロジェクトとは、Google Cloud Platformにおけるトップレベルコンテナです。
サービス利用時に最初に設定します。
プロジェクト名は任意の名前ですが、プロジェクトIDはGoogle Cloud Platform全体でグローバルな値である必要があるのでユニークなIDを設定します。
プロジェクトIDはあとで変更することが不可能なので、慎重に命名してください。
弊社では以下のように、3つのプロジェクトを作成しています。
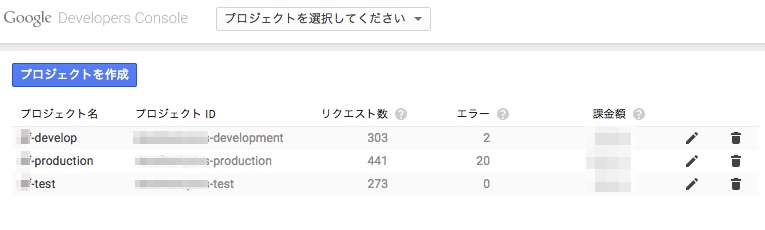
プロジェクトIDの命名
弊社ではプロジェクトIDを以下のように命名しています。
用途が一目でわかりやすいのもそうですが、例えば、Railsで利用する場合は、コード内でプロジェクトIDを"xxxx-#{Rails.env}"と参照できるので便利です。
| プロジェクトID | 用途 |
|---|---|
| xxxx-development | 開発用 |
| xxxx-production | 本番用 |
| xxxx-test | テスト用 |
データセットとは
データセットとは、BigQueryで扱うテーブルの集合です。
テーブルを作成するときは、このデータセットを事前に作る必要があります。
データセットの命名に関する注意点
データセットを数字から始まる名前で作成した場合は、クエリを実行する際に下記のように[]で囲まないとエラーになるので注意が必要です。
SELECT hoge_column FROM [20150304_load.hoge_table]
BigQueryでもJOINはボトルネックになる
冒頭で触れたとおり、BigQueryはクエリが爆速です。
ですが、JOINを使うと話は別です。
弊社のプロジェクトでBigQueryに投げているクエリには、JOIN(又はJOIN EACH)がふんだんに使われていて、結果が返ってくるまで10分以上かかります。
扱ってるデータは400〜500万行程(5〜6GB)です。
BigQueryはそのパフォーマンスゆえ、雑なクエリを投げることに抵抗はありませんが、JOINを使う場合はクエリの最適化が必要かもしれないので注意が必要です。
APIでのクエリの実行方法は2種類ある
BigQueryではクエリを実行するAPIメソッドが2つあります。
Jobs.queryとJobs.insertです。
両者の違いはいくつかあります。
その中でも代表的なのはポーリング(クライアントから一定間隔でサーバに対し情報の取得要求を行うこと)が必要かどうかという点です。
つまり、クエリの実行方法に同期と非同期の2種類があるということです。
- Jobs.queryはポーリングが不要
- Jobs.insertはポーリングが必要
google-api-ruby-clientでは以下のように書きます。
Jobs.queryでクエリを実行する場合
require 'google/api_client'
client = Google::APIClient.new(application_name: 'sample', application_version: '0.0.1')
# 〜認証まわりのコードは省略〜
api = client.discovered_api('bigquery', 'v2')
parameters = {
api_method: api.jobs.query,
parameters: {
projectId: 'sample_project'
},
body_object: {
query: 'SELECT COUNT(*) FROM [publicdata:samples.wikipedia]'
}
}
# クエリを実行する
response = client.execute(parameters)
response.data.rows[0].f[0].v.to_i
# => 313797035
Jobs.insertでクエリを実行する場合
require 'google/api_client'
client = Google::APIClient.new(application_name: 'sample', application_version: '0.0.1')
# 〜認証まわりのコードは省略〜
api = client.discovered_api('bigquery', 'v2')
parameters = {
api_method: api.jobs.insert,
parameters: {
projectId: 'sample_project'
},
body_object: {
configuration: {
query: {
query: 'SELECT COUNT(*) FROM [publicdata:samples.wikipedia]'
}
}
}
}
# クエリを実行する
response = client.execute(parameters)
parameters = {
api_method: api.jobs.get,
parameters: {
projectId: 'sample_project', jobId: response.data.jobReference.jobId
}
}
response = client.execute(parameters)
# ポーリングする
while response.data.status.state != 'DONE'
sleep 30
response = client.execute(parameters)
end
parameters = {
api_method: api.jobs.get_query_results,
parameters: {
projectId: 'sample_project',
jobId: response.data.jobReference.jobId
}
}
# クエリの結果を取得する
response = client.execute(parameters)
response.data.rows[0].f[0].v
# => 313797035
両者のユースケース
Jobs.queryは、クエリが実行完了し結果が返ってくるまで待ってくれます。
よって、テーブルのデータ件数のカウント等、クエリの結果が小さい場合に利用すると良いです。
逆に、クエリの結果が大きい場合や別テーブルに結果を保存したい場合は、より柔軟なユースケースに対応できるJobs.insertを使うべきです。
Jobs.queryは、クエリの結果が小さい場合に利用すべきJobs.insertは、クエリの結果が大きい場合や別テーブルに結果を保存したい場合に利用すべき
ポーリングは自前で実装する
上述のJobs.insertのサンプルコードでも行ってますが、弊社では、以下の流れでポーリングを行っています。
Jobs.insertでクエリ実行ジョブを投げる- レスポンスからジョブIDを取得
- 取得したジョブIDに紐づくジョブのステータスを
Jobs.getで取得 - ステータスが"DONE"になるまで3を繰り返す
- エラー時の処理
Jobs.getQueryResultsでジョブIDに紐づくクエリの結果を取得
基本的な流れは公式リファレンスに記載されている例と同様です。
別テーブルにクエリの結果を保存する場合は6の手順は不要です。
ジョブのステータスは、"PENDING"→"RUNNING"→"DONE"と遷移していきます。
注意しなければならないのは、ジョブの成否に関わらず最終的に"DONE"になることです。
5でエラー時の処理を行っているのはそのためです。
エラーの場合は、ステータス取得時のレスポンスの"status.errorResult"というフィールドに値が入ってるのでその存在有無でエラーハンドリングを行います。
エラーハンドリングの例
# ポーリングする
while response.data.status.state != 'DONE'
sleep 30
response = client.execute(parameters)
end
if error_result = response.data.status.try(:[], 'errorResult')
raise "Failed. reason: #{error_result.to_json}"
end
分割エクスポートの話
BigQueryのテーブルは、エクスポート可能です。
エクスポート方法やファイル形式等の詳しい説明はリファレンスを参照してください。
なお、1つのファイルにエクスポートできるサイズは1GBまでです。
よって、1GB以上のテーブルをエクスポートする場合は、分割してエクスポートする必要があります。
また、gzip形式に圧縮した上でのエクスポートもできます。
Google Cloud Storageに5GBほどのテーブルをエクスポートしてみたところ、約20ファイル程のgzipファイルが出来上がりました。
5GBだからなんとなく5ファイルできそうな気がしますが、BigQuery側が並列に複数ファイルに書き込むので1つのファイルのサイズはバラバラになりますし、サイズ指定もできません。
リトライの自前実装
BigQueryに対するクエリの実行はたまに失敗します。
だいたいはリトライすれば解決しますが、そのためにはリトライ機構を自前実装しなければなりません。
google-api-ruby-clientにはリトライの機能がありますが、現時点では回数しか指定できません。
よって、「5分間隔でリトライしたい」等の細かい指定はgoogle-api-ruby-clientではできません。
弊社では、kamui/retriableというgemを使ってリトライの自前実装を行っています。
また、このgemはgoogle-api-ruby-clientの内部でも使われているので、自前実装と言ってもモンキーパッチ的な実装で済むのでそれほど難しくはありません。
retriableを使う場合の注意点
retriableはgoogle-api-ruby-clientの内部でも使われているgemですが、retriableのメジャーバージョンを1.x系に固定してます。
よって、retriableの使い方を調べる際は、1.x系のREADMEを読んでください。
リトライのサンプルコード
google-api-ruby-clientではexecuteというメソッドでリクエストを投げているので、以下のように実装することで、失敗時にリトライができるようにしました。
module RetryExecute
def execute(*args)
# 10分間隔で最大6回リトライする
Retriable.retriable tries: 6, interval: 10.minutes do
super
end
end
end
Google::APIClient.class_eval do
prepend RetryExecute
end
まとめ
- google/google-api-ruby-clientはalpha版にも関わらず、十分有用。
- abronte/BigQueryの利用は、今回は断念しましたが、PRによる改善次第では将来性があると思います。また、プロダクションでの初のBigQuery利用だったので、まずは公式で示してあるgemを使って安心したかったというのが正直な理由としてあります。
- 弊社では1クエリ10分以上かかってしまうクエリを投げていますが、それでもちゃんと結果を返してくれるBigQueryは優秀だと思います。普通のDBでは中々実行に躊躇するクエリだと思います。
- ジョブの成否に関わらず、ステータスが"DONE"になるのは結構罠。
- 分割エクスポートは、結局Ruby側でダウンロードして結合しなければいけないので面倒でした。
- リトライの自前実装はみんなどうやってるんだろう。

新しいブログへ移行しました!こちらもよろしくお願いします。