
こんにちは。増田です。Amazon で PS4 Pro の料金が定価に戻っていたので、日曜日にうっかりポチッとしてしまいました。今日も元気です。
先月、RDS for MySQL を 5.5.40 から 5.5.53 にアップデートしました。今月で MySQL 5.5.40 のサポートが切れ、強制アップデートされるためです。
私が対応するのは今回で 3 回目になりますが、今までは Staging 環境で検証した後、深夜作業で Apply Immediately もしくは Reboot していました。
今回は MySQL のメジャーアップデートではないため、問題が起きる可能性は少ないのですが、仮に問題があった場合にロールバック出来ません。
そのため、出来るだけ安全側に倒してアップデートしてみました。この記事を書くことで、属人化を廃することを期待していたり、もっと良いやり方があれば知りたいという意図もあります。
今回意識したこと
- サービスのダウンタイムを出来るだけ減らす
- 問題が起きた時に、出来るだけ早くロールバック可能な状態にしておく
- 深夜作業前に出来ることは全部やり、当日やることを減らす
- 当日に時間のかかりそうな処理は、事前に確認しておく
- 少しでも不安なことがあれば、不安がなくなるまで何度でもシミュレーションする
今回の構成
EC2 インスタンス上の Unicorn と delayed_job が RDS を参照する、標準的な構成になっています。master は Multi-AZ になっており、Read Replica が 1 台ぶら下がっています。

事前にやったこと
Qiita:Team の記事作成
深夜作業でやること、事前にやること、心配なこと、思いついたことなどをどんどん書いていきました。
Release Note の確認
5.5.40 から 5.5.53 までの Release Note を全部確認しました。
例: https://dev.mysql.com/doc/relnotes/mysql/5.5/en/news-5-5-53.html
Staging 環境でシミュレーション
公式の『わずかなダウンタイムでの MySQL データベースのアップグレード』に従って、Staging 環境でシミュレーションしました。
今回は一回やった後に、もっと良い方法を思いついたので、もう一回シミュレーションしました。
時間がかかりそうな処理を確認する
当日時間がかかりそうな master への昇格、Multi-AZ 化、Read Replica の作成などを、本番環境と同じデータで試し、時間の目安を把握しました。経験的に時間にブレがあることは分かっているので、あくまで目安です。
参考までに、以下は今回の検証でかかった時間です。
- スナップショット作成: 30 分程で完了
- master への昇格: 4 分以内に完了
- Multi-AZ 化: 9 分程度で完了
- Read Replica 作成: 12 分程度で完了
深夜のバッチ処理時間の把握
深夜に実行されるバッチ処理はあるため、作業時間に被らないように把握しました。
会社 PC を自宅で作業可能にしておく
会社の情報セキュリティポリシーに則り、持ち出せる状態にしておきます。
一部は IP アドレス制限しているため、それらもアクセス可能かを確認して、当日慌てないようにします。Zabbix や Bugsnag などのエラー監視ツールも見られるようにしておきます。
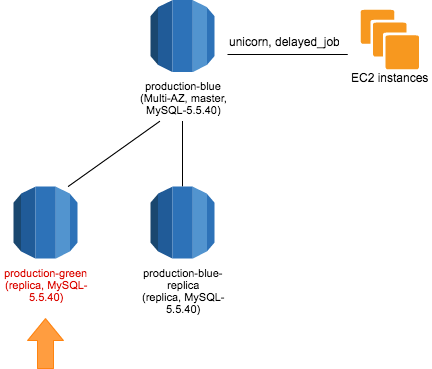
昇格用の RDS インスタンス作成とアップデート
昇格用の RDS インスタンス(以下 production-green)を master の Read Replica として作成しました。
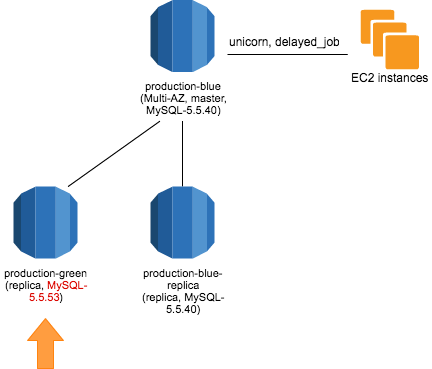
さらに MySQL 5.5.53 にアップデートしておきます。
深夜作業用の Pull Request の作成
予め、以下の Pull Request を作っておきました。
PR1- アプリケーションが参照する RDS のエンドポイントを前述の
production-greenに切り替える
- アプリケーションが参照する RDS のエンドポイントを前述の
PR2- 同様に Zabbix や fluentd のメトリクス収集元を切り替える
当日やったこと
仮眠
作業開始は AM1:30 からにしました。仮眠はもちろん取っておきます。深夜作業でお腹が空くのも辛いので、軽食を用意するのも良いでしょう。
スナップショットの作成
AM1:30 からスナップショットを取り始めました。結果的に 50 分程かかりました。
このスナップショットは DB がクラッシュした時の命綱です。自動バックアップで作られるスナップショットは RDS インスタンスを Delete すると削除されるので、要注意です。
今回は人力でやりましたが、cron などで自動化したほうが良いと思います。
アプリケーションの接続先を production-green に向ける
前述の PR1 をデプロイし、接続先を Read Replica に向けます。Webアプリケーションとしては read-only になります。PR2 も Cook して、メトリクス収集元を切り替えます。
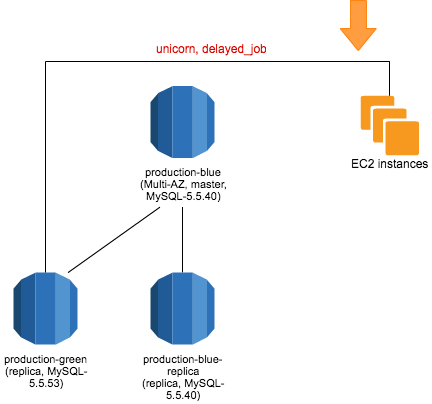
この状態での Write 系処理は、アプリケーションに 503 Service Unavailable を返させたほうが良いと思います。
production-green を master に昇格
昇格すると、production-blue との関係はなくなり、Web アプリケーションとして read-write 可能になります。今回は数分のダウンタイムが発生しました。
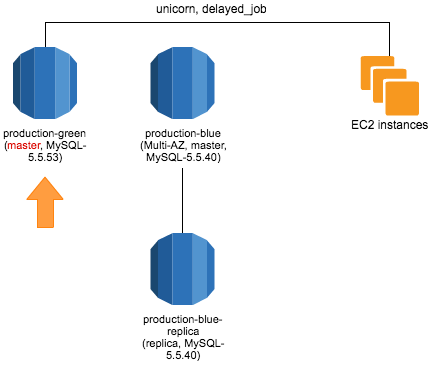
昇格時に RDS インスタンスが再起動しますが、delayed_job の場合、全てのプロセスが終了してしまいます。通知で気付けると思いますが、デプロイして起動し直す必要があります。
Multi-AZ にする
もうダウンタイムは発生しないので、ここからは安心して作業出来ます。
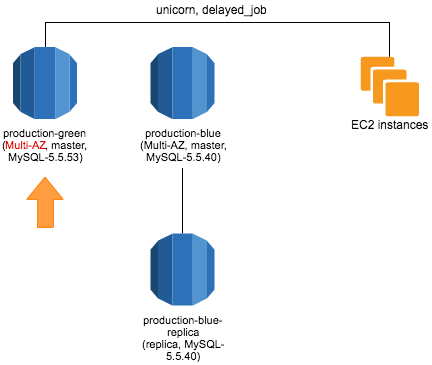
結果として、インスタンスが Single-AZ から Multi-AZ に変換される際には、ダウンタイムは発生しません。 by よくある質問 - Amazon RDS | AWS
Read Replica を作る
今回のサービスは、一部の処理を Read Replica に逃がしているので、作成します。
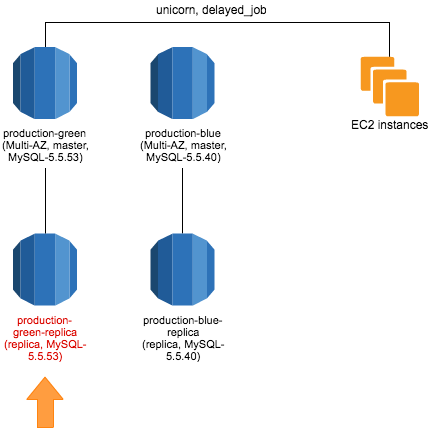
以前の RDS インスタンスを削除する
各種エラーがないことを確認できたので、次の日に削除しました。本当は翌営業日まで起動したかったのですが、コストと問題が起こる可能性を天秤にかけて、このようにしました。
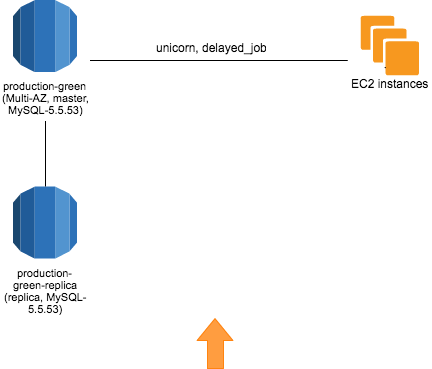
それでも問題は起こるもの
今回は production-green を master に昇格した後、一部のアカウントでログインできなくなりました。ログインできるアカウントもあり、作業中は深夜作業の長期化を覚悟しました。
しばらくしてジョブキューの数が閾値を超えたアラートが来たので、delayed_job プロセスが全部落ちていると気づき、再デプロイで復帰することが出来ました。
各 EC2 インスタンスの delayed_job プロセス数は当然監視しています。今までアラートが来なかったことはなかったので、今でも本当に謎です。後日試したら速攻でアラートが来ました。
とは言え、深夜作業に問題はつきものです。今回はこれだけ準備した上での問題だったので、悔いや後悔はありません。
終わりに
今回はとにかく、ダウンタイムをゼロに近づけ、ロールバックも可能にすることを目的にしました。そのために出来る準備は全部やり、深夜作業でやることや考えることをできるだけ減らしました。
深夜作業はいつもより頭が回らないものです。自分を過信せず、準備に準備を重ねることが非常に重要です。
現在は残念ながら「production-green を master に昇格」で数分のダウンタイムが発生してしまいます。今後はこちらを改善していきます。

新しいブログへ移行しました!こちらもよろしくお願いします。