
こんにちは。フィードフォース ボドゲ部の kano-e です。
こないだ『Last Night on Earth』というアメリカB級ゾンビ映画ゲーム(オリジナルサウンドトラック付き)で遊んで楽しかったのでまた遊びたい!
さて、最近 stretcher + consul を使ったアプリケーションのデプロイを tjinjin に布教1され、実際のプロダクト導入に向けてデモ用の環境で動かしています。
- これまでの (capistrano を使った) デプロイとの違い
- stretcher や consul が何をしているか
- 良い点と現状の課題
について、社内勉強会で話した内容をまとめます。
これまでの capistrano でのデプロイ
これまでの capistrano を使ったプロダクトのデプロイは、以下のようなフローでした
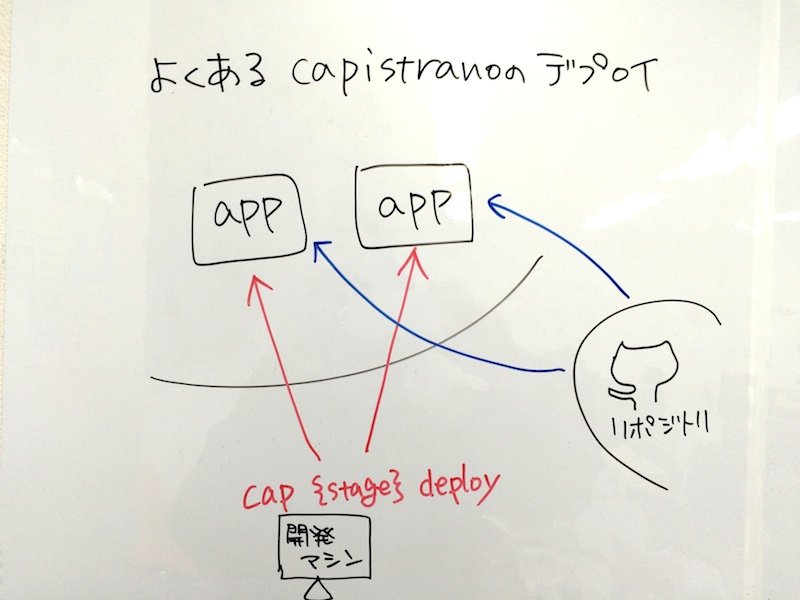
cap production deploy などと実行するだけですので、普段はタスクの中身をそこまで意識することはありませんが、ざっくりとタスクの流れを追うと
- アプリケーションサーバ (デプロイ対象サーバ) に SSH で接続
- 各アプリケーションサーバからリポジトリに接続してコードを持ってくる
- アプリケーションが動くために必要な処理 (
bundle installなど) を各アプリケーションサーバで実行
といったことを実行しています。
stretcher + consul + capistrano でのデプロイ
capistrano に加えて stretcher + consul を導入し、デプロイのフローは以下のようになりました。
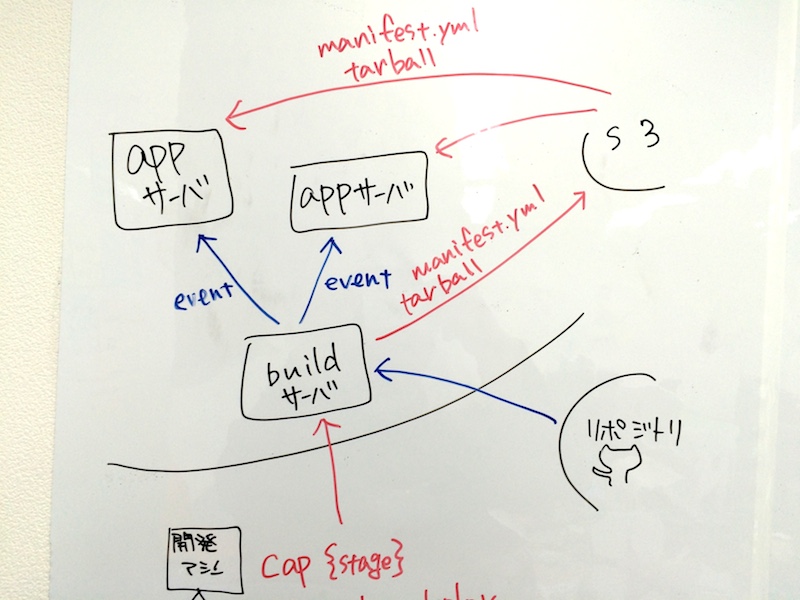
- ビルドサーバに SSH で接続
- ビルドサーバからリポジトリに接続してコードを持ってくる
- アプリケーションが動くために必要な処理 (
bundle installなど) もビルドサーバで実行 - アプリケーションのコードを tarball にして、manifest.yml と合わせて s3 にアップ
- デプロイ イベントを発行
- デプロイ イベントを受け取った各アプリサーバが s3 から manifest.yml と tarball をダウンロード、配備
なんだか急に登場人物も増えたし capistrano だけの時よりも複雑……?
いったい誰が何をして、何が嬉しいのか、もう少し詳しく調べてみます。
もっと詳しく!
stretcher
さっきのフローの中で stretcher が担当している箇所は
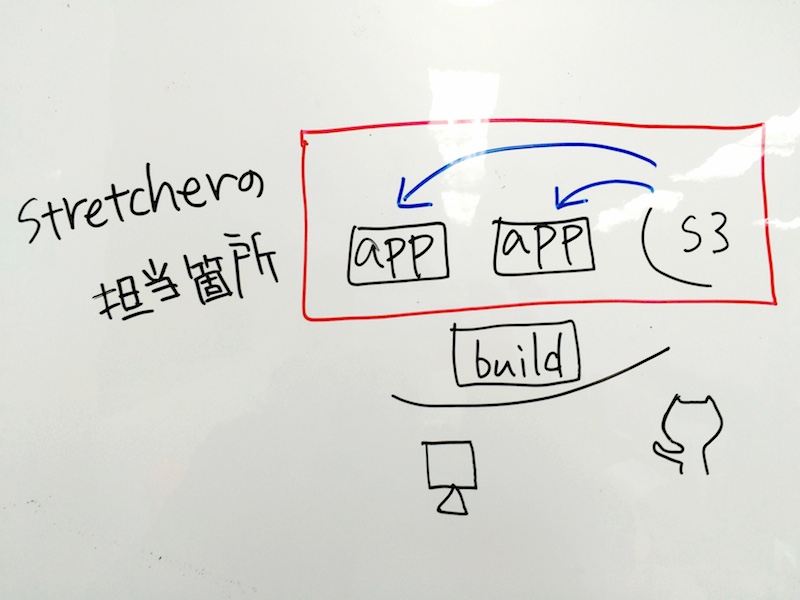
s3 から manifest.yml と tarball をダウンロードして配備するところです。
stretcher は manifest.yml の置き場所を渡されると、それをダウンロードして中身を確認します。
manifest.yml には
- tarball の在処
- tarball の checksum
- tarball をどこに展開するか
- 作業前後で実行したい処理 (シェルスクリプト)
が書かれています。
manifest.yml の中身を確認した stretcher は、指定された tarball をダウンロードして、指定された場所に展開し、指定された処理を実行します。
consul
consul の担当箇所は
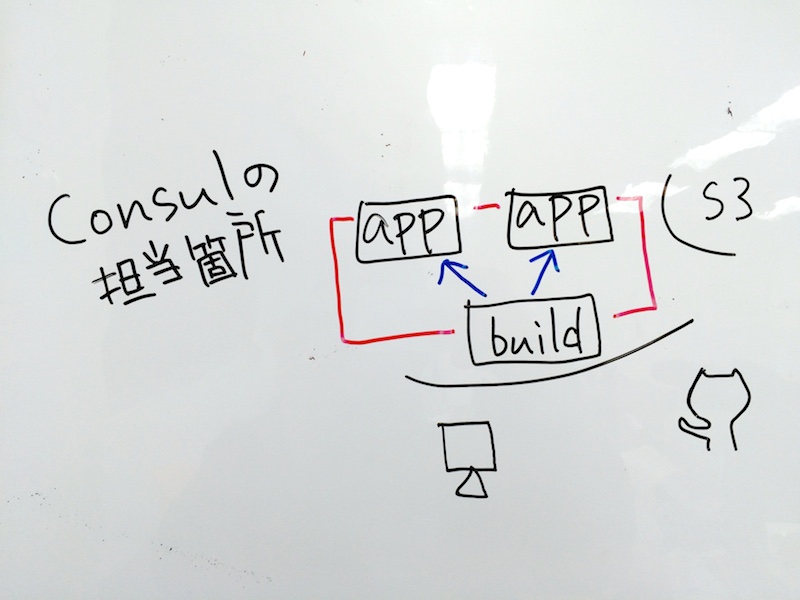
各サーバ間でのイベントのやり取り部分です。
先ほどの例だと consul は、アプリケーションサーバとビルドサーバにいて、クラスタというものを組んでサーバを管理しています。
イベントが発生するとクラスタ内のサーバに対してイベントが伝播します。
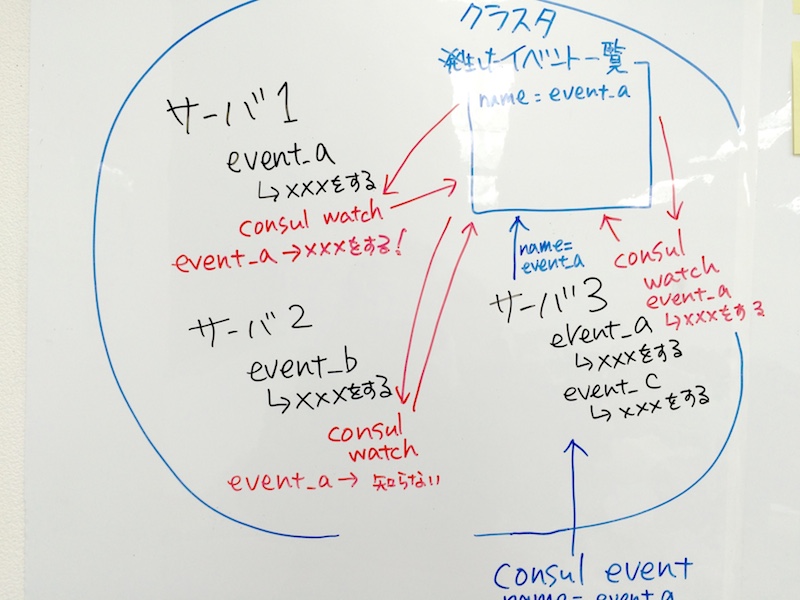
この例だと サーバ1, サーバ2, サーバ3 の3台でクラスタを組んでいます。
サーバ1には event_a が発生した時の処理が、サーバ2には event_b の処理が、サーバ3には event_a と event_c の処理がそれぞれ登録されています。
クラスタ内では発生したイベントを溜めておく場所があります。イベントが発生すると、まずそこに登録されます。
クラスタ内の各サーバで新しいイベントの発生を監視し、新しいイベントが発生するとそれを受け取ります。
event_a というイベントが発生した時には、サーバ1とサーバ2が、それぞれ登録された処理を実行します。
サーバ2も event_a を受け取りますが、サーバ2の知らないイベントなので何もしません。
デプロイの時には、各アプリケーションサーバにデプロイイベントが発生したら stretcher を起動するように設定しておき、デプロイしたい時には consul event でデプロイイベントを発生させる、といった使い方をしています。
capistrano
capistrano の担当はそれ以外全部です。
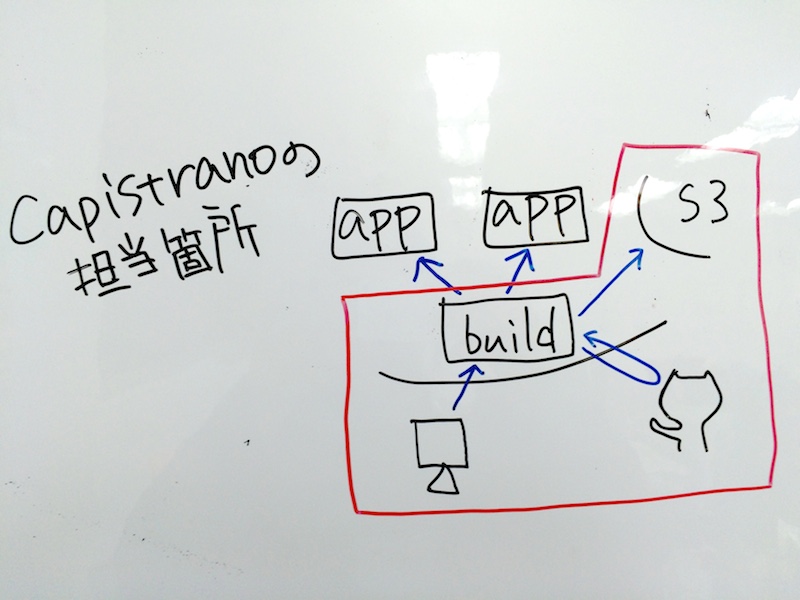
- リポジトリから checkout
bundle install,db:migrate,assets:precompile- tarball を作成して s3 にアップ
- manifest を環境毎に作成して s3 にアップ
- consul event を実行
ほとんど capistrano-stretcher, capistrano-stretcher-rails を利用して実行しています。
今までの "お馴染み" の capistrano とはだいぶ違うのですが、一番大きいのは
app ロールを定義しない = アプリケーションサーバの情報を capistrano が知らない
ということではないでしょうか。
capistrano の deploy タスクは、基本的に app ロールに対して実行されるので cap deploy しても何も起こらなくなります。
(少し不便だったので cap deploy で stretcher:deploy が実行されるようにしました)
アプリケーションサーバに接続しないので、当然ながら unicorn や sidekiq などのプロセスの再起動も capistrano では実行しません。
それらの処理は stretcher がデプロイ後に実行することとして manifest.yml に定義します。
シンボリックリンクの張り替えなども manifest に書く必要があります。
current のシンボリックリンクや log, tmp/pids については capistrano-stretcher にデフォルトで設定されていますが、それ以外については自分で設定しておく必要があります。
デプロイ時に実行したいスクリプトは環境毎に設定でき、capistrano-stretcher が環境毎に manifest.yml を作成してくれます。
こちらのサーバでは unicorn を reload, こちらのサーバでは sidekiq というということも、そこで指定することになります。
良いところ
capistrano や開発マシンで、アプリケーションサーバのことを気にしなくて良くなったことが大きいです。
今後、アプリケーションサーバの増減や接続先IPアドレスなどの情報を考えなくても良くなるため、デプロイの設定がずいぶん楽になりました。
また bundle install や assets:precompile などの処理は、ビルドサーバで1回だけしか実行されないのも嬉しいです。
本番サーバで一斉に bundle install が始まってしまってしまって負荷が……みたいな心配からは解放されます。
今後の課題
デプロイの失敗検知をどうするか、というのは現状検討中のところです。
今はまだ台数が少ないので把握できていますが、台数が増えたら中の1台の失敗について把握できるかどうか、という懸念はあります。
また unicorn reload が実は失敗していて、表向き問題は出ていないけど実は古い状態のプロセスが残っていて……という状態に気付けるかどうか、というのも考えているところです。
ほかの課題としては、まだ stretcher や consul 周りに詳しい人が社内に少ないため、布教してくれた tjinjin に頼りっぱなしになっていることでしょうか。
今回の社内勉強会でも、返答できない質問の時には代わりに回答してもらったりなど、よりかかりまくっています。
これについては、今後追いつけるように頑張る所存でおります。
これから
まだ導入したばかりで見えてるもの・見えてないものどちらの課題もたくさんある状態ですが、
- ビルドとデプロイをもっと分離したい
- DB のスキーマ変更のタイミングもデプロイから分離したい
- ほかのプロダクトでも導入できるかもしれない
などなど、期待もいっぱい浮かんできています。
より安全で、開発者にとっても負担の少ないデプロイになると良いなあ。
ということを考えながら、今は stretcher + consul + capistrano を使ったデプロイを導入しています。
-
http://cross-black777.hatenablog.com/entry/2016/01/23/190211
ほかにも Qiita:Team への記事アップや vm 環境を使ったデモなどすごく勉強になりました! ↩

新しいブログへ移行しました!こちらもよろしくお願いします。